 About The Forum
About The ForumSpotlight Research Projects
|
The Butte Laboratory builds and applies tools that convert more than 400 trillion points of molecular, clinical, and epidemiological data -- measured by researchers and clinicians over the past decade -- into diagnostics, therapeutics, and new insights into disease. Examples of this method includes work on cancer drug discovery published in the Proceedings of the National Academy of Science (2000), on type 2 diabetes published in the Proceedings of the National Academy of Science (2003 and 2012), on fat cell formation published in Nature Cell Biology (2005), on obesity in Bioinformatics (2007), and in transplantation published in Proceedings of the National Academy of Science (2009). To facilitate this, the Butte Lab has developed tools to automatically index and find genomic data sets based on the phenotypic and contextual details of each experiment, published in Nature Biotechnology (2006), to re-map microarray data, published in Nature Methods (2007), to deconvolve multi-cellular samples, published in Nature Methods (2010), and to perform these calculations on the internet "cloud", as published in Nature Biotechnology (2010). The Butte Lab has used these tools on publicly-available molecular data to successfully find and validate new uses for existing drugs, as published in back-to-back papers in Science Translational Medicine (2011) and Cancer Discovery (2013). The Butte Lab has also been developing novel methods in comparing clinical data from electronic health record systems with gene expression data, as described in Science (2008), and was part of the team performing the first clinical annotation of a patient presenting with a whole genome, as described in the Lancet (2010).
|
|||
|---|---|---|---|
 Translational Bioinformatics
Translational Bioinformatics|
ChucK is a programming language for audio and music creation. The language is designed around a unique time-based, concurrent programming model that's precise and expressive (we call this strongly-timed), and the ability to add and modify code on-the-fly. It offers composers, researchers, and performers a powerful programming tool for building and experimenting with complex audio synthesis/analysis programs, and real-time interactive music.
|
|||
|---|---|---|---|
 ChucK: A Music Programming Language
ChucK: A Music Programming Language|
Ocarina, created in 2008 for the iPhone, is one of the first musical artifacts in the age of pervasive, app-based mobile computing. It presents a flute-like physical interaction using microphone input, multitouch, and accelerometers – and a social dimension that allows users to listen-in on each other around the world. To date, Ocarina has over 10 millions users worldwide, and was a first-class inductee into Apple's Hall of Fame Apps.
|
|||
|---|---|---|---|
 Ocarina: Designing the iPhone's Magic Flute
Ocarina: Designing the iPhone's Magic Flute|
The Stanford Laptop Orchestra (SLOrk) is a large-scale, computer-mediated ensemble and classroom that explores cutting-edge technology in combination with conventional musical contexts - while radically transforming both. Founded in 2008 by director Ge Wang and students, faculty, and staff at Stanford University's Center for Computer Research in Music and Acoustics (CCRMA), this unique ensemble comprises more than 20 laptops, human performers, controllers, and custom multi-channel speaker arrays designed to provide each computer meta-instrument with its own identity and presence. The orchestra fuses a powerful sea of sound with the immediacy of human music-making, capturing the irreplaceable energy of a live ensemble performance as well as its sonic intimacy and grandeur. At the same time, it leverages the computer's precision, possibilities for new sounds, and potential for fantastical automation to provide a boundary-less sonic canvas on which to experiment, create, and perform music.
Offstage, the ensemble serves as a one-of-a-kind learning environment that explores music, human-computer interaction, design, composition, and live performance in a naturally interdisciplinary way (it's also a cross-listed course in Music and Computer Science). SLOrk uses the ChucK programming language as its primary software platform for sound synthesis/analysis, instrument design, performance, and education.
|
|||
|---|---|---|---|
 SLOrk: Stanford Laptop Orchestra
SLOrk: Stanford Laptop Orchestra|
Energy-efficient computing platforms are sorely needed to control autonomous robots and to decode neural signals in brain-machine interfaces. Inspired by the brain’s energy efficiency, we are exploring a hybrid analog-digital approach that uses subthreshold analog circuits to emulate graded dendritic activity and asynchronous digital circuits to emulate all-or-none axonal activity. We have used this approach to build Neurogrid, a sixteen-chip neuromorphic system that can simulate biophysically-detailed cortical models with up to a million neurons and six billion synaptic connections in real-time while consuming a few watts. We are now using this approach—together with a formal method that maps arbitrary nonlinear dynamical systems onto spiking neural networks—to develop a new breed of neuromoprhic chips that can be programmed to perform arbitrary computations. Our goal is to develop a programmable neuromorphic chip with a million neurons and a billion synaptic connections that consumes tens of milliwatts—a hundred times more energy-efficient than Neurogrid. When seamlessly interconnected by on-chip routers to build spiking neural networks with millions of silicon neurons and billions of synaptic connections, these chips offer a promising alternative for robotic and prosthetic applications.
|
|||
|---|---|---|---|
 Neuromorphics: Compiling Code by Configuring Connections
Neuromorphics: Compiling Code by Configuring Connections|
The PIs of this NSF-sponsored project are Prof. Leonid Kazovsky (Stanford), Prof. Vincent Chan (MIT), and Prof. Andrea Fumagalli (UT-Dallas).
UltraFlow is a secure, agile and cost-effective architecture that will replace legacy Electronic Packet Switching (EPS), specifically for its ability to enable very large file transfers (terabits of data) in a fast and efficient manner. At Stanford, our mandate is to design and experimentally demonstrate UltraFlow Access, a novel last-mile network architecture that offers dual-mode Internet access to end users: IP and optical flow. The new hybrid Internet architecture is designed to be secure, dynamic (both agile and adaptive), and significantly more cost effective for future growth in data volumes and number of users. UltraFlow relies on a novel optical network architecture comprising new transport mechanisms and a new comprehensive control plane including network protocols from the physical layer up to the application layer. It also integrates the foregoing new network modalities with the conventional TCP/IP network architecture and provides multiple service types to suit any user needs.
|
|||
|---|---|---|---|
 UltraFlow: A Hybrid Future Internet Architecture
UltraFlow: A Hybrid Future Internet Architecture|
We are developing nanoscale electronic devices and circuits to emulate the functions of the synapses and neurons of the brain. The goal is to use nanoscale electronic devices to do information processing using algorithms and methods inspired by how the brain works. Currently, we are using phase change memory and metal oxide RRAM to perform gray-scale analog programming of the resistance values. These electronic emulations of the synapse are then connected in a neural network to process information and achieve simple learning behavior.
In the past few years, we have been able to emulate a variety of spike-timing dependent plasticity (STDP) behaviors of the biological synapse using these nanoscale electronic devices. Using larger arrays of electronic synapses, we study how device variations affect system performance. The stochastic nature of the switching process of these devices has a rich set of properties that may be utilized for many applications.
In the future, it may be possible to use these nanoscale electronic devices to study how the brain works, by interfacing these devices directly with biological entities.
|
|||
|---|---|---|---|
 Brain-Inspired Computing
Brain-Inspired Computing|
For transistors it is important to have an atomically thin channel that enables gate length scaling while maintaining good carrier transport required for a high current drive. At the same time, parasitic resistance from the contacts and parasitic capacitance from the device structure must be minimized. Currently, we are working on the use of carbon nanotube (CNT) and two-dimensional layered materials (the transition metal dichalcogenide family of materials) as the atomically thin channel. We are also working on techniques to minimize the contact resistance and the parasitic capacitance. By building practical systems of these emerging technologies, we learn how to solve device and materials problems that have system-level impact.
|
|||
|---|---|---|---|
 Logic
Logic|
I started doing research on memory devices around 2003. Research on memory had been rather “predictable” for many years until recently. It was predictable because the major advances for memory devices involved scaling down the physical dimensions of essentially the same device structure using basically the same materials. The situation has changed in the last decade. Memory devices are beginning to be difficult to scale down. But perhaps the most important change is that new applications and products (e.g. mobile phones, tablets, enterprise-scale disk storage) in the last decade are often enabled by advances in memory technology, in particular solid-state non-volatile memories.
Our research on memory devices focuses on phase change memory (PCM) and metal oxide resistive switching memory (RRAM). We work on understanding the fundamental physics of these devices and develop models of how they work. We explore the use of various materials and device structures (e.g. 3D vertical RRAM) to achieve desired characteristics. We often utilize the unique properties of nanoscale materials such as carbon nanotube, graphene, and nanoparticles to help us gain understanding of the physics and scaling properties of memory devices.
|
|||
|---|---|---|---|
 Memory
Memory|
3X is an open-source software tool to ease the burden of conducting computational experiments and managing data analytics. 3X provides a standard yet configurable structure to execute a wide variety of experiments in a systematic way, avoiding repeated creation of ad-hoc scripts and directory hierarchies. 3X organizes the code, inputs, and outputs for an experiment. The tool submits arbitrary numbers of computational runs to a variety of different compute platforms, and supervises their execution. It records the returning results, and lets the experimenter immediately visualize the data in a variety of ways. Aggregated result data shown by the tool can be drilled down to individual runs, and further runs of the experiment can be driven interactively. Our ultimate goal is to make 3X a “smart assistant” that runs experiments and analyzes results semi-automatically, so experimenters and analysts can focus their time on deeper analysis. Two features toward this end are under development: visualization recommendations and automatic selection of promising runs.
|
|||
|---|---|---|---|
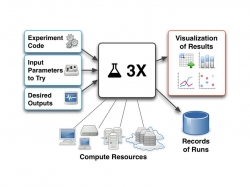 3X: A Workbench for eXecuting eXploratory eXperiments
3X: A Workbench for eXecuting eXploratory eXperiments|
Deep learning is a rapidly growing area of machine learning, that is becoming widely adopted within academia and industry. Whereas machine learning is a very successful technology, applying it today still often requires spending substantial effort hand-designing features to feed to the algorithm. This is true for applications in vision, audio, and text/NLP. To address this, Ng's group and others are working on "deep learning" algorithms, which can automatically learn feature representations (often from unlabeled data), thus bypassing most of this time-consuming engineering. These algorithms are based on building massive artificial neural networks, that were loosely inspired by cortical (brain) computations. One our group's most celebrated results in deep learning is a highly distributed neural network with over 1 billion parameters trained on 16,000 CPU cores (at Google), and that learned by itself to discover high level concepts--such as "cats"---from watching unlabeled YouTube video.
For a high-level overview of the field, see the following video.
|
|||
|---|---|---|---|
 Deep Learning
Deep Learning|
The Salisbury Lab conducts research in the areas of robotics,
medical robotics, haptic devices and haptic rendering algorithms. One project is developing a virtual environment that enables
surgeons to plan and practice surgical procedures by interacting
visually and haptically with patient-specific data derived
from CAT and MRI scans. Our lab developed the first version of the personal robot (PR-1), which eventually was licensed to Willow Garage and was the genesis of the PR-2 personal robot. We continue to develop robot hands, addressing design, control and perceptual issues. Our team is typically
a mix of students from computer science, mechanical engineering and mathematics as well as practicing surgeons.
|
|||
|---|---|---|---|
 Salisbury BioRobotics Laboratory
Salisbury BioRobotics Laboratory|
The Red Sea Robotics Research Exploratorium was created in April 2012 through a generous research award from the King Abdullah University of Science and Technology (KAUST)
|
|||
|---|---|---|---|
 The Red Sea Robotics Exploratorium
The Red Sea Robotics Exploratorium|
About
The Red Sea Robotics Research Exploratorium was created in April 2012 through a generous research award from the King Abdullah University of Science and Technology (KAUST). As a part of the KAUST Global Collaborative Research Program, Stanford University is part of a team of universities working to build a major science and technology university along a marshy peninsula on Saudi Arabia’s western coast. Meka Robotics joined the collaboration and provides the hardware for the development of dexterous underwater robot arms.
|
|||
|---|---|---|---|
 The Red Sea Robotics Exploratorium
The Red Sea Robotics Exploratorium|
This video production documents the life and career of Ed Feigenbaum, "Father of Expert Systems," through archival photographs, a Computer History Museum oral history, and the recollections of his collaborators and students. These recollections were videotaped at the Feigenbaum 70th Birthday Symposium, held on
March 25-26, 2006 and co-sponsored by the Stanford Computer Forum.
|
|||
|---|---|---|---|
 Ed Feigenbaum's Search for A.I.
Ed Feigenbaum's Search for A.I.|
ImageNet is an image dataset organized according to the WordNet hierarchy. Each meaningful concept in WordNet, possibly described by multiple words or word phrases, is called a "synonym set" or "synset". There are more than 100,000 synsets in WordNet, majority of them are nouns (80,000+). In ImageNet, we aim to provide on average 1000 images to illustrate each synset. Images of each concept are quality-controlled and human-annotated. In its completion, we hope ImageNet will offer tens of millions of cleanly sorted images for most of the concepts in the WordNet hierarchy.
|
|||
|---|---|---|---|
 'ImageNet: A Large-Scale Hierarchical Image Database'
'ImageNet: A Large-Scale Hierarchical Image Database'|
Given an image, we propose a hierarchical generative model that classifies the overall scene, recognizes and segments each object component, as well as annotates the image with a list of tags. To our knowledge, this is the first model that performs all three tasks in one coherent framework. For instance, a scene of a ‘polo game’ consists of several visual objects such as ‘human’, ‘horse’, ‘grass’, etc. In addition, it can be further annotated with a list of more abstract (e.g. ‘dusk’) or visually less salient (e.g. ‘saddle’) tags. Our generative model jointly explains images through a visual model and a textual model. Visually relevant objects are represented by regions and patches, while visually irrelevant textual annotations are influenced directly by the overall scene class. We propose a fully automatic learning framework that is able to learn robust scene models from noisy web data such as images and user tags from Flickr.com. We demonstrate the effectiveness of our framework by automatically classifying, annotating and segmenting images from eight classes depicting sport scenes. In all three tasks, our model significantly outperforms state-of- the-art algorithms.
|
|||
|---|---|---|---|
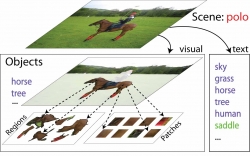 Towards Total Scene Understanding:Classification, Annotation and Segmentation in an Automatic Framework
Towards Total Scene Understanding:Classification, Annotation and Segmentation in an Automatic Framework|
An artist might spend weeks fretting over questions of depth, scale and perspective in a landscape painting, but once it is done, what's left is a two-dimensional image with a fixed point of view. But the Make3d algorithm, developed by Stanford computer scientists, can take any two-dimensional image and create a three-dimensional "fly around" model of its content, giving viewers access to the scene's depth and a range of points of view.
|
|||
|---|---|---|---|
 Make3D
Make3D|
Stanley and the Stanford Racing Team were awarded 2 million dollars for being the first team to complete the 132 mile DARPA Grand Challenge course. Stanley finished in just under 6 hours 54 minutes and averaged over 19 miles per hours on the course.
The Grand Challenge, first held in March 2004, is an off-road robot competition devised by DARPA to promote research in the area of autonomous vehicles. The challenge, in general terms, is to build a robot capable of navigating without human intervention over 130 miles of rough terrain in less than 10 hours.
Calling this task a Grand Challenge is not an exaggeration! The 2004 course started in Barstow, California (1.5 hours outside of Los Angeles) and ended in Primm, Nevada. The most successful competitor navigated only 7.5 miles out of the 142 mile course.
We invite you to visit www.stanfordracing.org to check on our progress!
|
|||
|---|---|---|---|
 DARPA Grand Challenge
DARPA Grand Challenge|
Since 1996, research on light fields has followed a number of lines. On the theoretical side, researchers have developed spatial and frequency domain analyses of light field sampling and have proposed several new parameterizations of the light field, including surface light fields and unstructured Lumigraphs. On the practical side, researchers have experimented with literally dozens of ways to capture light fields, ranging from camera arrays to kaleidoscopes, as well as several ways to display them, such as an array of video projectors aimed at a lenticular sheet.
Researchers have also explored the relationship between light fields and other sampled representations of light transport, such as incident light fields and reflectance fields. At Stanford, we have focused on the boundary between light fields, photography, and high-performance imaging, an area we sometimes call computational photography. However, our research also touches on other aspects of light fields, such as interactive animation of light fields and computing shape from light fields.
|
|||
|---|---|---|---|
 Light Fields & Computational Photography
Light Fields & Computational Photography|
The Common Password Problem. Users tend to use a single password at many different web sites. By now there are several reported cases where attackers breaks into a low security site to retrieve thousands of username/password pairs and directly try them one by one at a high security e-commerce site such as eBay. As expected, this attack is remarkably effective.
A Simple Solution. PwdHash is a browser extension that transparently converts a user's password into a domain-specific password. The user can activate this hashing by choosing passwords that start with a special prefix (@@) or by pressing a special password key (F2). PwdHash automatically replaces the contents of these password fields with a one-way hash of the pair (password, domain-name). As a result, the site only sees a domain-specific hash of the password, as opposed to the password itself. A break-in at a low security site exposes password hashes rather than an actual password. We emphasize that the hash function we use is public and can be computed on any machine which enables users to login to their web accounts from any machine in the world. Hashing is done using a Pseudo Random Function (PRF).
Phishing protection. A major benefit of PwdHash is that it provides a defense against password phishing scams. In a phishing scam, users are directed to a spoof web site where they are asked to enter their username and password. SpoofGuard is a browser extension that alerts the user when a phishing page is encountered. PwdHash complements SpoofGuard in defending users from phishng scams: using PwdHash the phisher only sees a hash of the password specific to the domain hosting the spoof page. This hash is useless at the site that the phisher intended to spoof.
|
|||
|---|---|---|---|
 PwdHash - Web Password Hashing
PwdHash - Web Password Hashing|
Volumetric models of facial musculature enable highly realistic computer simulations of visual speech and expressive face motion. This research addresses the performance, control and analysis challenges that arise from the simulation of such high detail models and caters to both computer graphics and medical applications.
Realistic simulation and analysis of facial expressions is an open research problem with a wide range of potential applications such as special effects, communications, visual speech synthesis and maxillofacial medicine. The goals of visual realism and biophysical accuracy suggest a clear advantage for simulation methods that respect the anatomy of the face by modeling the tissue composition of the flesh and employ the underlying musculature as the driving force behind the formation of expressions.
This project involves the development of novel algorithms for increasing the computational performance of high resolution face models by several orders of magnitude, enhancing the quality of all visual elements involved in the simulation and providing convenient, intuitive and efficient ways of controlling the motion of the face, for example using easy to obtain motion capture data.
|
|||
|---|---|---|---|
 Simulation & Analysis of Muscle Actuated 3D Face Models
Simulation & Analysis of Muscle Actuated 3D Face Models|
Increasing use of computers and networks in business, government, recreation, and almost all aspects of daily life has led to a proliferation of online sensitive data, i.e., data that, if used improperly, can harm the data subjects. As a result, concern about the ownership, control, privacy, and accuracy of these data has become a top priority. This project focuses on both the technical challenges of handling sensitive data and the policy and legal issues facing data subjects, data owners, and data users.
|
|||
|---|---|---|---|
 PORTIA: Managing sensitive information in a wired world
PORTIA: Managing sensitive information in a wired world